
I recently learned about TF-IDF as a measure of a words importance to a document and thought it would be an interesting idea to investigate with keywords in SEO. While many professionals have discounted TF-IDF as an effective tool for content optimization, I think that it is a unique way to analyze content for the use of keywords and to build out keyword research. Beyond that, it is another way for me to practice my R Programming skills, so read on!
What is TF-IDF?
TF-IDF stands for Term Frequency-Inverse Document Frequency and is a weight of how important a term is to a document relative to other documents in the same collection. Let’s take a look at the formula:
TF-IDF = (Count of Term i)/(All Terms in Document) * log[(Total Number of Documents)/(Total Number of Documents Containing Term i)]
It multiplies how frequently a term is used in a document (Term Frequency) by how often it appears in all the documents of the same collection (Inverse Document Frequency). Term Frequency is a bit self-explanatory, so let’s breakdown what “IDF” means a bit more.
In this equation, the “IDF” metric is what allows us to measure the importance of a term beyond just how many times the term appears in a document. It does this by assigning a higher weight to terms that show up less frequently in the document – the words that provide meaning and context to the document – while taking the log of the inverse ratio helps to weigh down frequent terms like “is” and “the” – the words that do not provide meaning or context.
Sometimes, terms can have an IDF of score of zero, which would cause the term to have a TF-IDF score of zero as well, and then it won’t seem important to our analysis. To ensure that this does not happen, we can do IDF smoothing, which involves adding 1 to the log of the IDF ratio.
Why use TF-IDF for SEO?
In the world of SEO, we can think of a term as a search query or target keyword and all websites as our collection of documents. Similar to how TF-IDF measures the importance of a term in a document relative to a collection of documents, Search Engines have to compare websites against each other to see which ones provide the best answer to a search query.
While it is not known if TF-IDF is a SEO ranking factor or how much of a TF-IDF-related analysis is involved in a Search Engine, at the end of the day, a Search Engine is just an algorithm looking for webpages with content related to a search query.
Search engines are going to pay attention to how well a page matches search intent, this means that the keywords you are targeting need to be considered “important” in your content. If your target terms don’t stand out in your content, then how can a search engine detect them? What words you use, and how use them impact your ability to rank and land on Page 1 of Search Engine Result Pages (SERPs). TF-IDF tells you what words are important in your content, and if this does not match your intended output, then we have a bit of a problem.
As an SEO, think about TF-IDF as an “importance” score – is my target keyword more important to my content relative to other top performing pages? For competitor sites, TF-IDF can tell you what words are considered important to your competitor, while SEO tools just tell you what keywords they rank for.
How can TF-IDF be used for SEO?
Not that you understand why you would want to utilize TF-IDF for you SEO, let’s go over some ways that you can actually do this.
- With TF-IDF you can analyze your existing content to see if your target terms are considered “important” relative to top-performing competitors.
- Vice versa, you can analyze competitors to see how “important” your target terms are to their pages.
- You can also use TF-IDF to build out unconventional keyword research by seeing what other terms are considered “important” on your top competitor pages.
Where can I do TF-IDF?
You might be wondering, “okay, great – where do I actually do this?” Now, you could pay for existing software or use free trials or free daily limited TF-IDF analysis with tools like Seobility or Ryte. You could also do fully customizable analysis, as many times as you want for completely free with R!
TF-IDF is just a formula that you can simply program with R. Beyond just the TF-IDF analysis, RStudio, R’s development environment, provides you with a workspace to scrape text data directly from the web, clean and prepare your data for analysis and visualize your results. So, why not use R?
If you are new to R and RStudio, here is a brief intro with links on how to get to started. Now let’s get to some TF-IDF action.
Putting TF-IDF for SEO into Action
To put TF-IDF with R into action, I decided to use one of my previous blog posts on the documentary “Data Science Pioneers: Conquering the Next Frontier” and compared it to webpages that ranked on Page 1 for the target term “Data Science Pioneers.” In an ideal world, I would have a large collection of webpages to get an accurate TF-IDF value, but for this example I will just stick to two. The top-performing pages that I ultimately used were Dataiku’s “Documentary Data Science Pioneers Hits the Big Screens” page, which is no surprise since the documentary is made by Dataiku, and Optimal BI’s “Data Science Pioneers Movie” page, another company that hosted a screening of the documentary.
For those who want to follow along in R, Click Here for my reference code.
Step 1: Scrape Text from Webpages
My first step was to scrape the text from each of these webpages. R’s ‘rvest’ package allows you to read the contents of any URL into R, and select the specific information (HTML nodes) that you want to import. To find these HTML nodes you can use the Chrome extension ‘SelectorGadget‘ to simply select the text that you need and it will provide you with the HTML node for that text. For a more detailed explanation on how to scrape text with ‘rvest’, Click Here for an example from one of my previous posts.
Step 2: Create & Clean the Corpus
Now, with the text from each of these webpages, I need to turn them each into a “Corpus,” or a collection of text, in order to do further analysis. Using the ‘Corpus‘ package in R and the term_stats() function allows you to tokenize the words in the text and create a data frame with each term and the number of times the word appears in the text. The term_stats() function also allows you to clean the text by removing punctuation. For a more detailed example on creating and cleaning a Corpus, you can reference the ‘rvest’ example linked above.
Let’s take a look at the “jtds” (Journey to Data Scientist) data frame:

Step 3: Creating the “TF” Metric
Now, I can move into to calculating the “TF-IDF” metric, but before I do that, I need to create the “TF” and “IDF” metrics first. Let’s focus on just “TF” for right now. Term Frequency is just the ratio of the number of times the word appears in the document to all words in the document.
In the current data frame, there is one column for the “word” and another column for the “count” of the word. All I need to do is add another column for the count of “total_words”, which is just the sum of the “count” column. Then I can create an additional column for the “TF” metric using the “count” and “total_words” columns. I simply had to use the “dplyr” function mutate() in order to add these new columns to the existing data frame. Let’s take a look at the code below where I mutated the “jtds” data frame to include the new columns:
jtds <- jtds %>%
mutate(source = "Journey to Data Scientist") %>%
mutate(total_words = sum(jtds$count)) %>%
mutate("TF" = count / total_words)
Let’s look at a preview of the new “jtds” data frame:

You can now see the columns for “total_words” and “TF” columns. You will also notice that I have added a column to indicate which document (website) the term is from. You might wonder why this is necessary when this is only the “jtds” data frame, but you will understand why in just a second.
Step 4: Creating the “IDF” and then the “TF-IDF” Metrics
Now, that I have the Term Frequency for all three webpages, I need to calculate the Inverse Document Frequency. Remember, the equation for IDF = log[(Total Number of Documents)/(Total Number of Documents Containing Term i)]. So, I need the total number of documents, which is 3 in this case, and the total number of documents containing each term. The latter is a bit trickier to calculate.
This is where assigning the source document comes in handy. I need to find the total number of documents each term appears in. How can I do this? By combining my three existing data frames into one using the rbind() function and then finding the count (n) of each term in the one new data frame. This new count will be the number of webpages that the term is present in. The “source” column allows me to differentiate between which webpage each term came from. Let’s take a look at the code to bind the data frames:
combined_dataframe <- rbind(jtds, di, ob)
Now, to calculate the “IDF” and “TF-IDF” metrics, I can use group_by(source) to make sure they stay separate by webpage. For the calculation, I first need to find the count (n) of how many times each term appears in the new combined data frame (or the number of webpages that it is present in). Then, I can create the “IDF” column (IDF = log(3/n)) and then the “TF-IDF” column (TF * IDF) using the mutate() function. Let’s take a look at the code for this:
tf_idf <- combined_dataframe %>%
add_count(word) %>%
group_by(source) %>%
mutate("IDF" = 1 + log(3 / n)) %>%
mutate("TF_IDF" = TF * IDF)
Similar to how I mutated the “jtds” data frame to add the “TF” metric, I did the same to the new combined_dataframe by first adding the count, grouping by source and then calculating the “IDF” and “TF-IDF” metrics. Let’s preview the “tf_idf” data frame:
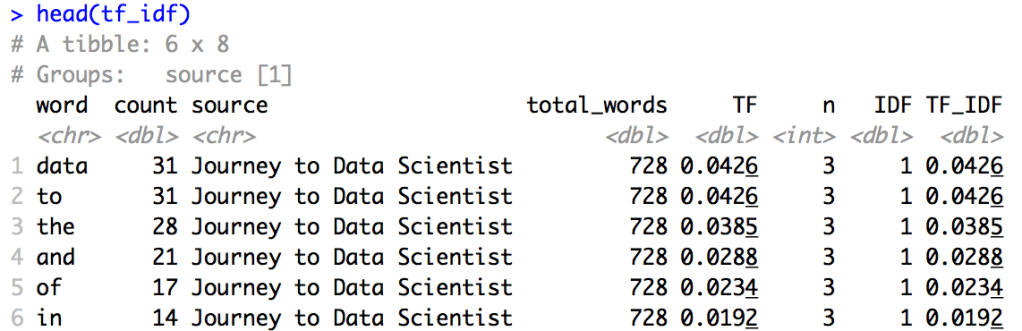
Finally – the TF-IDF metrics for all terms on the webpage, along with competitor webpages!
Step 5: TF-IDF Analysis
Now that I have the “TF_IDF” metric, I can compare this metric for target keywords on my webpage versus my top competitor webpages. To do this, I first want to create a new data frame filtering for the terms that I am interested in looking at. For now, I will look at the keywords: data, science, scientists, dataiku, ai, pioneers, machine, documentary, screening, learning, artificial and intelligence. Then, I can plot their TF-IDF scores against each other in a bar chart:

From the chart we can see that my blog post did pretty well for these target terms. It has the highest TF-IDF metric for 3 keywords: “data”, “science” and “machine”. This means that these three keywords appear to be more “important” to my webpage, than my competitors’ webpage. Both Dataiku and Optimal BI also had the highest TF-IDF metrics for four keywords each. So, each webpages is winning in “importance” for some term, and are at least showing up for these target terms.
These results aren’t really compelling me to change my target keywords or content, so let’s now take a look at some of the terms with highest TF-IDF metrics across all webpages:

You will notice that the majority of the keywords with the highest TF-IDF metrics are common words like “the” and “and”. So, despite our efforts minify their impact, these common terms are still being weighted as important. One way to solve this issue is to remove these common terms from the beginning of the analysis, but that would affect the overall TF-IDF metric, which requires the count of all words…just something to work on.
You will also notice that the words “film” and “movie” are considered to be important to Dataiku and Optimal BI, but not my blog post. Maybe these are keywords I could optimize for if I were to rewrite this content. Of course, I would look beyond just these highest scored words, and look at what other words competitors are using as well. When using any tools to build out keyword research, you also always need to pay attention to what keywords are relevant to your content (this is where being a human trumps being a machine.) What a great way to build out keyword research!
Well there you have it – how you can use TF-IDF for SEO with R.
Some things to work on in the future:
Now, there are obviously some kinks to work out. So, in the future, I would like to first find a way to minify the effect of common words even more. Next, I would like to find a way to analyze long-tailed keywords and not just one term. I would also like to find a way to use more webpages as part of my “collection of documents.” A larger goal would be to turn this into a Shiny Web App where we have a nice interface to automatically extract data from the web, generate potential keyword lists etc….wish me luck!
In the mean time, try it out for yourself by writing content, checking your TF-IDF scores in comparison to your competitors, discovering new keywords to use, and seeing how you perform with them! I also want to emphasize that you should not replace your regular keyword research or content optimization with TF-IDF, this is just a different lens to look at how keywords are used within content.
Sources used to write this post:
Barysevich, Aleh. “TF-IDF: Can it Really Help Your SEO?”. Search Engine Journal. https://www.searchenginejournal.com/tf-idf-can-it-really-help-your-seo/331075/
Diggity, Matt. “TF*IDF for SEO: Test Results and Tool Comparison”. Diggity Marketing. https://diggitymarketing.com/tfidf-for-seo/
Howland, PJ. “How to Crush Your Competitors With TF-IDF”. MOZ. https://moz.com/blog/tf-idf-for-seo
Jeske, Stephen. “Why TF-IDF Doesn’t Solve Your Content and SEO Problem but Feels Like it Does.” MarketMuse. https://blog.marketmuse.com/why-tf-idf-doesnt-solve-your-content-and-seo-problem-but-feels-like-it-does/

Hi Anisha,
Really good article with detailed explanation. I’ve also read https://github.com/AnishaB95/Blog-Posts/blob/master/TF-IDF_for_SEO_with_R.Rmd and I’m wondering what’s the reason you didn’t capture /html/body/div[1]/div[2]/div/div[1]/main/article/header? This is the source of my confusion; what should/shouldn’t be part of the tf-idf analysis (figcaption, h, …).
I’d appreciate if you could shed more light on that topic.
LikeLike
Hi Greg, thanks for your question. I think that text got messed up when you submitted the comment and I cannot read the entire thing, maybe you copy and pasted something? Could you ask the question again? Thanks.
LikeLike