
Text Sentiment Analysis in R
Today, we celebrate the life of Martin Luther King Jr., his achievements as a civil rights leader and his fight against racial segregation and racism in the United States. There is no doubt that MLK Jr.’s “I Have a Dream” speech is one of the most powerful speeches known, invoking great emotion about the hardships faced due to racial segregation, but also the hope for a future where everyone can be seen as equal.
I wanted to take this opportunity to examine the words used in his speech to understand the emotions behind it. Specifically, I wanted to perform a text sentiment analysis of his speech to understand what sentiments are related to the words that he used and what is the overall sentiment of his speech; whether it be a negative or positive message based on the text.
To keep things organized, I have split this post into the following sections:
- Scraping Text from a Webpage
- Creating and Cleaning the Text Corpus
- Top 10 Words Used in the Speech
- Text Sentiment Analysis
- Joining Speech Words with Sentiment Dictionaries
- A Look at Positive and Negative Sentiments in the Speech
- A Look at Specific Emotions in the Speech
For those who want to follow along in R, click here for the reference code.
Scraping Text from a Webpage
My first step was to import the speech into R. Now, I did not have an Excel or CSV file with the speech text, so I decided to scrape the speech text from a webpage using the ‘rvest’ package. ‘rvest’ allows you to read the HTML code of any URL into R, and select the specific information (HTML nodes) that you want to import.
I found a copy of the “I Have a Dream” speech on HuffPost’s website. In order to scrape just the speech text from the webpage, I had to find the webpage’s HTML nodes associated with just the speech text. If you are not tech savvy, that’s okay, I simply used the Chrome extension ‘SelectorGadget‘ to just click on the speech text on the webpage and it provided me with the HTML node:
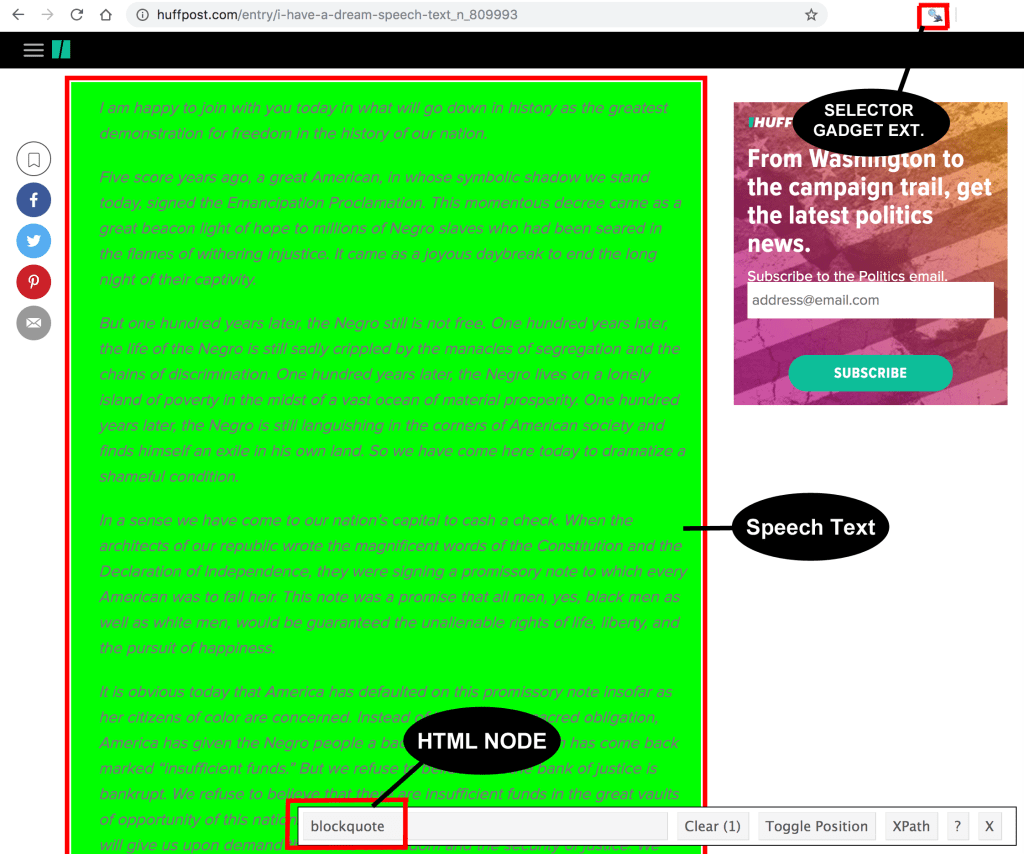
Once I found the HTML node for the speech text, which was “blockquote” in this case, I could import the text into R with the following code:
#Create the URL variable for desired webpage to be scraped
url <- 'https://www.huffpost.com/entry/i-have-a-dream-speech-text_n_809993'
#Read in the webpage HTML code and specific nodes (information) wanted from the webpage
webpage <- read_html(url)
speech_text <- html_nodes(webpage,'blockquote')
#Convert nodes to text
speech_text <- html_text(speech_text)
Here’s a screenshot showing a snippet of what ‘speech_text’ looks like in R:

And that’s the first step! Text scraped from a webpage with the ‘rvest’ package in R. For more information on web scraping, take a look at this Beginner’s Guide on Web Scraping in R.
Creating and Cleaning the Text Corpus
The next step before performing a text sentiment analysis is to turn the speech text into a Corpus, which is a set of texts. Using the ‘Corpus‘ package and the term_stats() function allows you to tokenize the words in the text and create a data frame with each word and the word’s frequency. The term_stats() function also allows you to clean the text by removing punctuation and stop words, common words like “a,” “the” and “and,” which do not provide context or meaning to the text.
Let’s take a look at the R code for creating and cleaning a corpus:
#Create Corpus
data <- as_corpus_frame(speech_text)
#Create table and remove punctuation and stop words from the Corpus:
words <- term_stats(data, drop_punct = TRUE, drop = stopwords_en)
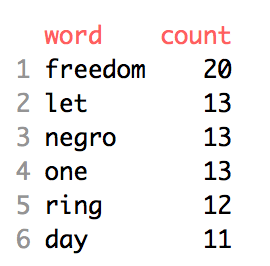
Take look at the preview of the new data frame. We now have the words from the speech and the number of times the word appears in the speech.
Top 10 Words Used
With the new data frame, I then created a bar graph to see the top 10 words used in MLK Jr.’s speech:
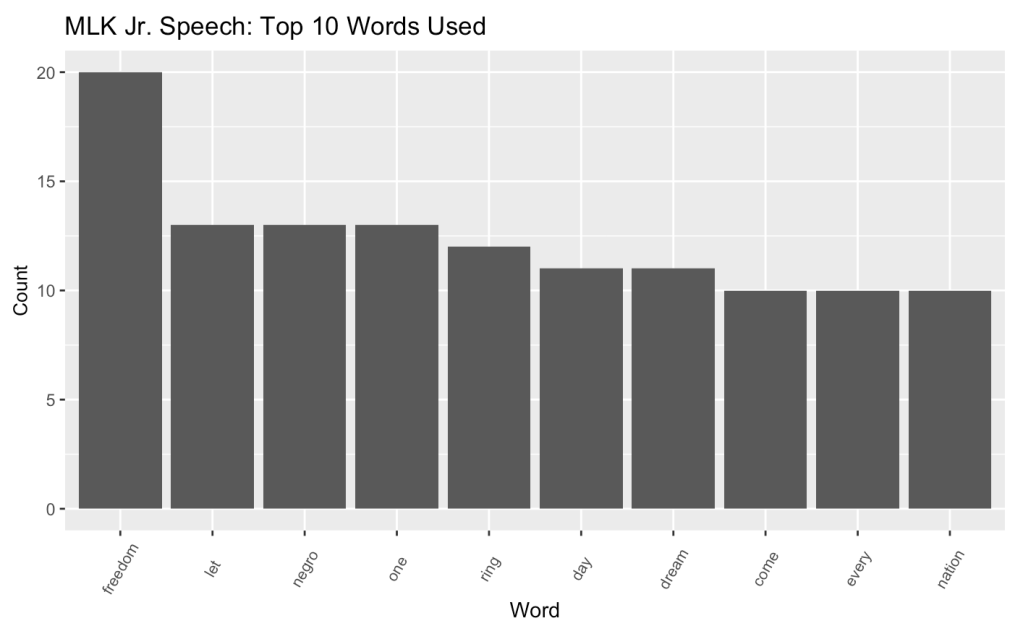
From the graph, we can see that the top used word is “freedom,” appearing 20 times in the speech. Other notable top words used are “negro,” “dream” and “nation”; all integral to the message of this speech.
While this bar graph does not contain any sentiment analysis yet, I do want you to take note of what the top 10 words are and to compare to the text sentiment analysis version later.
Text Sentiment Analysis
Now, we can talk about the text sentiment analysis. In R, the package ‘tidytext,’ which is used for data mining, includes a data set called sentiments. This data set consists of three dictionaries of words with assigned sentiments: AFINN, Bing and NRC. For this sentiment analysis I just used the Bing and NRC dictionaries. The Bing dictionary assigns words with positive and negative sentiments, while the NRC dictionary assigns words based on the following emotions: positive, negative, trust, sadness, joy, fear, anticipation, anger, disgust and surprise.
The core part of this text sentiment analysis is being able to relate the sentiments of these dictionaries to the words used in the “I Have a Dream” speech. This involves joining the two data frames together – the data frame with the words from the speech and each of the ‘tidytext’ data frames with the dictionary of words and their sentiments. The data frames will be joined by the words that are common between them.
To give an example: we know that the word “freedom” is used in the speech. If the word “freedom” also exists in the Bing dictionary and has a “positive” sentiment, our new data set with be joined based on the common word “freedom” and will be assigned with the “positive” sentiment. This will be done for all possible matches between the speech words and the sentiment dictionaries. With that, let’s get to the actual code.
Joining Speech words with Sentiment Dictionaries
The first step is to join the speech words data frame with both the Bing and the NRC sentiment dictionaries using the function inner_join():
#Join Speech Words and Bing Dictionary
speech_bing <- words %>%
inner_join(get_sentiments("bing"), by="word")
#Join Speech Words and NRC Dictionary
speech_nrc <- words %>%
inner_join(get_sentiments("nrc"), by="word")

Our new data frames, now have columns: “word”, “count” and “sentiment”. Here’s a preview of ‘speech_bing’:
A Look at Positive and Negative Sentiments in the Speech
First I took a look at positive and negative sentiments in the text. Specifically, I wanted to compare the count of words with positive sentiment to those with a negative sentiment. This meant that I needed to order both sentiments by “word count,” which I did by creating a new data frame with just two columns: “sentiment” and “word count.” Here is the code for doing that:
speech_bing_plot <- speech_bing %>%
group_by(sentiment) %>% # group words by sentiment
summarise(word_count = n()) %>% # find count of words by sentiment group
ungroup() %>% # separate words
mutate(sentiment = reorder(sentiment, word_count) # add column sentiment with sentiment ordered by word count
And here is the bar graph showing the comparison:
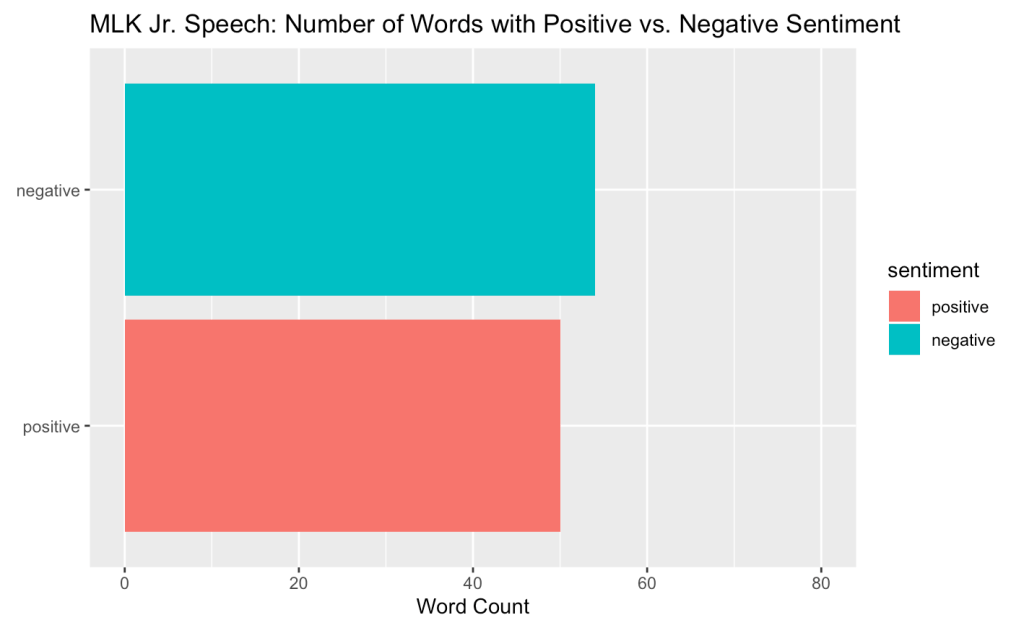
From the graph we can see that there are more words in the speech with a negative sentiment associated with it than a positive sentiment. However, the difference between the two is quite small.
Next I wanted to know exactly which words had what sentiment. I could just peruse through the data frame, but for visualization purposes I plotted the top 25 words used. While the bar graph above shows the word count for each sentiment, you have to remember that words do appear more than once, meaning that their sentiment is communicated more than once. This why we want to see the sentiments for the most used words:

As we can see, the top five words used all have positive sentiments associated with them: “freedom,” “satisfied,” “faith,” “free” and “great.” This paints a different story from the bar graph above, which showed that there is more negative sentiment than positive. Rather, words with a positive sentiment appear more int he speech. A great example of why it is important to look at data from different perspectives.
Another thing I want to note here, if you recall the “Top 10 Words Used” graph from above, do you see the same words here? You will notice that some of them are missing. This is because when the data frame with the speech words and the Bing dictionaries were joined, the resulting data frame only included words that matched between the two. Our original speech words data frame contained 464 words, while the joined data frame contains 104; this only represents 22.4% of the words in the speech.
So, unfortunately, any text sentiment analysis is unlikely to include all words from the original text; just something to keep in mind.
A LOOK AT Other SENTIMENTS IN THE SPEECH
After covering positive and negative sentiments in the speech, I wanted to look at more specific emotions with the NRC dictionary:

Starting at the top, we can see that there are more words with positive than negative sentiments. This is different from what was seen with the Bing dictionary, which indicated there are more words with negative sentiments. In fact, the NRC dictionary has more matches to the speech words than the Bing dictionary, matching with 377 out of the 464 words and representing 81.3% of the words in the speech. Therefore, the NRC dictionary provides a better opportunity to analyze the sentiment of the speech.
After positive and negative, the emotions with the most words are trust, sadness, joy and fear; a clear split between positive and negative-related sentiments. Again, it is important to remember that not only do words appear more than once, but words can have more than one sentiment. Therefore, I decided to create a bar graph of the top 10 words used faceted by sentiment. This would allow me to see the different emotions related to one word, and how the sentiments are represented in the top 10 words used:
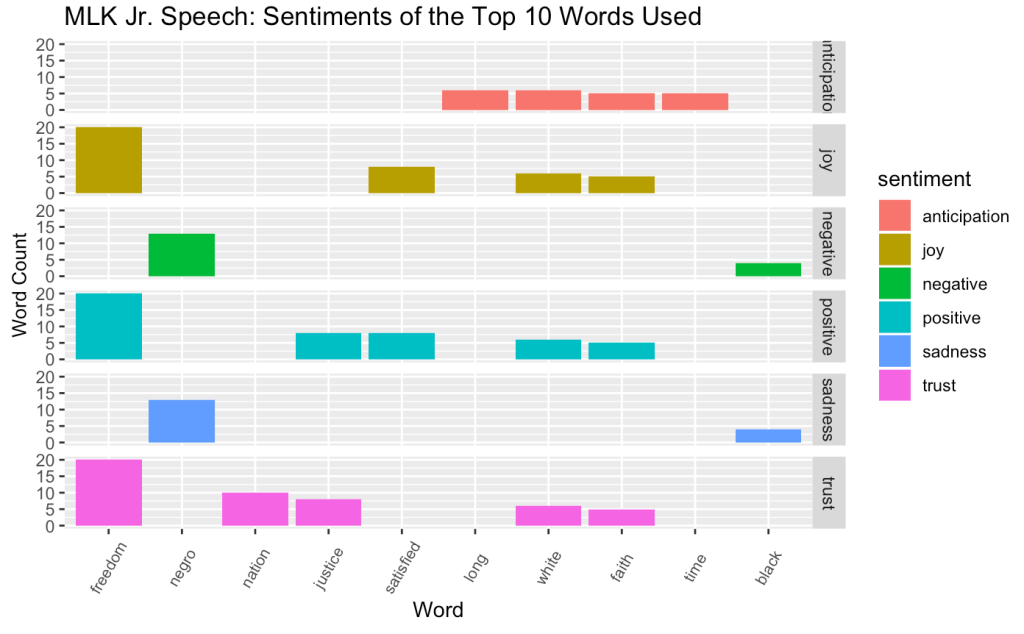
We can now see the emotions attributed to each word. For example, the word “faith” falls within the sentiments: trust, positive, joy and anticipation. We can also see how the sentiments are represented in the top 10 words used, which shows that positive-related sentiments show up 4-5 times, while negative-related sentiments only show up twice. Similar to the top words used from the Bing dictionary, we get a sense of a more positive message being presented in the speech.
The most shocking find from this graph is that the only two words associated with negative and the sadness emotions are “negro” and “black”. Why is it that the word “black” is thought of as a negative thing, while the word “white” is associated with trust, positive, joy and anticipation?
Not to mention, that this is how these words are represented in a modern-day digital dictionary; this is not a thing of the past. These are the sentiments that we as a society have; it is rooted in our language, in the way that we think and that is what needs to change. This is exactly what Martin Luther King Jr. fought for, for the sentiments around different races to be seen as equal. While his speech, based on what we have seen in these graphs, represent a positive image of trust, joy and anticipation for a change to come, the most important words still don’t have the meaning that they should. Until these sentiments around “negro” and “black” change, the fight for racial equality is not over.
I hope you have enjoyed this deep dive into the sentiments behind the famous “I Have a Dream” speech, and if you are looking to do more text sentiment analysis, please check out this helpful tutorial for more information.

[…] node for that text. For a more detailed explanation on how to scrape text with ‘rvest’, Click Here for an example from one of my previous […]
LikeLike