
The job of an SEO is to ensure that websites are optimized and performing well on search engines for target keywords (the words people are using to search online). This involves performing keyword research on lists of target keywords to segment into relevant groups or clusters; a.k.a. keyword clustering. Clustering or grouping keywords paints an overall picture of user search behavior online which is critical to developing efficient SEO strategies. Manually, keyword clustering can take a very long time, but luckily, there are now several ways to automate this process!
A few months ago, I came across Remi Bacha, a SEO professional who uses R for SEO and co-founded Data SEO Labs, a training organization that teaches SEO strategies based on Data Science through conferences, trainings and articles.
In one of his blog posts, Remi shared how to automate the process of keyword clustering in R. In order to do this, he used a hierarchical clustering algorithm which measures the similarity between two keyword strings and groups them based on their edit distance; the minimum number of character changes needed to change the keyword string into another. Once I discovered this, I just had to try it out for myself and share it here.
While Remi’s post provides a keyword list to use, I thought I would create a list of my own. Using Answer the Public, I generated a list of keywords related to “christmas presents”. Following Remi’s reference code, I created the below cluster dendrogram (arrangement of clusters) for my keyword list:

The dendrogram shows which keywords are most similar by the own clusters, which in this case started with two general groups, and breaks down further and further into smaller clusters with the most similar keywords. The y-axis, in the case, represents the measure of closeness of individual keywords and clusters. The keywords themselves are hard to read in this plot, but viewing the cluster file itself shows how keywords are segmented. Below is a screenshot of the cluster file for my keyword list:
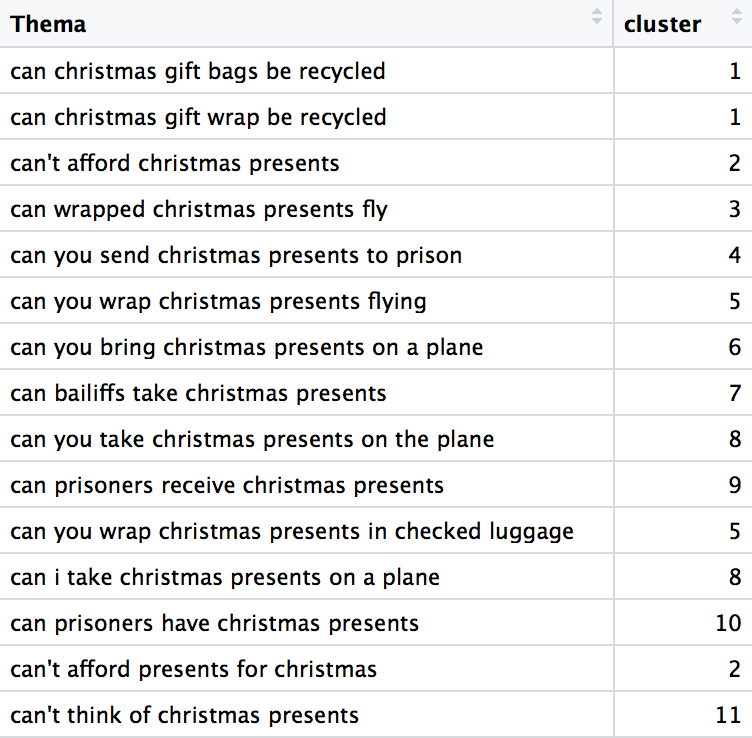
From the above we can see that the first two keywords “can christmas gift bags be recycled” and “can christmas gift wrap be recycled” have been grouped into the same cluster, but the third keyword “can’t afford christmas presents” has not. This is because it is too different based on the edit distance and is a completely different keyword with a different meaning. We can see, however, that “can’t afford christmas presents” and “can’t afford presents for christmas” have been grouped in the same cluster, which makes sense because they mean the same thing. “Can you wrap presents flying” and “can you wrap christmas presents in checked luggage” are also grouped in the same cluster.
Now, the more keywords you have in your keyword list, the more clusters you may end up with and may be hard to work with. An easy way to find the clusters with the most keywords (the more common themes among what users are searching) is by plotting a bar chart with the frequency of keywords per cluster:
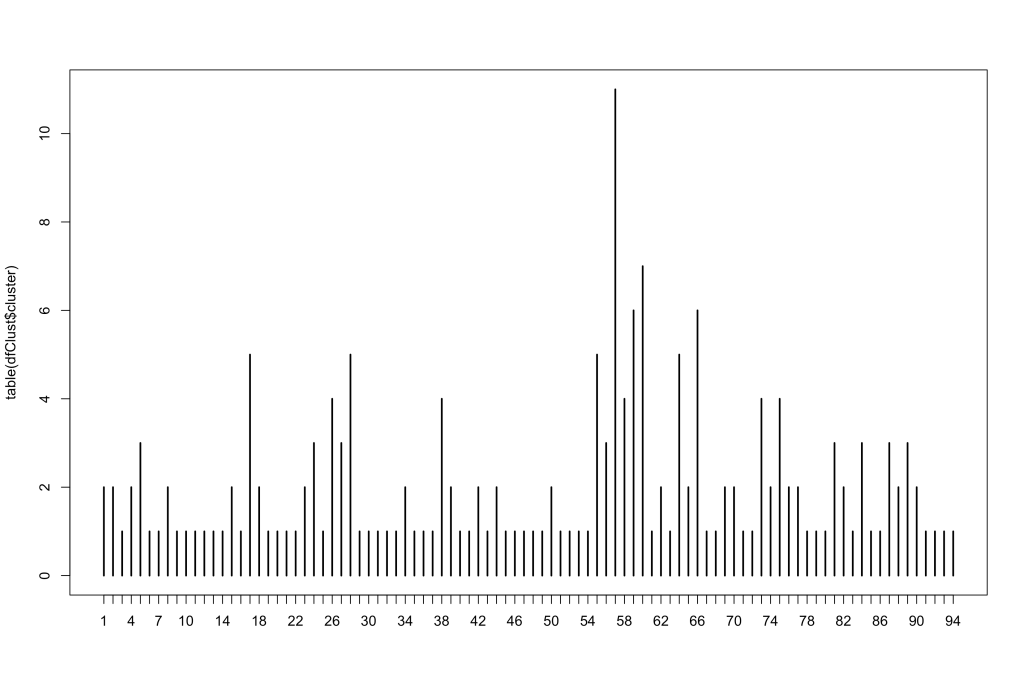
Now, if you wanted to find the most common keyword strings, you would just have to filter your cluster file for the cluster groups with the most keywords. In this case, I would definitely take a look at cluster number 57, which happens to include keywords starting with “christmas present for…”:

Thanks to Remi, anyone can now automate keyword clustering in R. He even went one step further by developing a kwClustersR function in R which can do all of the above for you in a single command!
Please click here for my reference code.

[…] a total of 828 visitors and 2,053 views. The blogs best day was December 9, 2019, when the “Keyword Clustering for SEO with R” post was […]
LikeLike