
Earlier this month, Data Science Salon hosted a webinar with Kevin Zielnicki, Machine Learning Architect at Stitch Fix. He spoke about Stitch Fix’s approach to personalized fashion recommendations and specifically, a novel model called the Client Time Series Model (CTSM).
Stitch Fix and Personalized Recommendations
For those who do not know, Stitch Fix is a personalized styling service that uses a combination of styling experts and data science to transform the way that people find clothes. When a new customer signs up, they fill out a profile with their styling preferences, a stylist puts together a fix with five items, and then the customer keeps what they want and returns what they do not like.
This is why personalized recommendations are so important at Stitch Fix, and it is the customers updated preferences over time that allow the recommendations to be as personalized as possible. There are several touchpoints that allow Stitch Fix to learn more about their customers which include initial profile sign-up, the Style Shuffle feature where users can rate different items, and feedback during checkout.
In the past, the probability of sale algorithm, which predicts whether a customer will purchase an item, has proven to be successful at increasing revenues and customer satisfaction. However, new kinds of user engagement data from different features (a.k.a. domains) on the Stitch Fix platform (ie. Fix checkout, Style Shuffle, Free Style, etc.) require more tailored models to generate recommendation predictions for each domain. This means more maintenance and overall more complexity.
Client Time Series Model
Stitch Fix introduced CTSM in order to generate better recommendations and manage the complexity of their models with three key elements.
The first element is unified client embeddings. Since Stitch Fix has to generate predictions for each platform domain from several user preference inputs for each customer, this means that they have to model several relationships or representations for each customer. This is called a many-to-many model (Figure 1). Stitch Fix decided to simplify the problem by creating one representation (or embedding) of each customer from all of their user preference inputs and using this one embedding to generate the recommendation predictions for the different platform domains. This approach is referred to as a many-to-one-to-many model (Figure 2).
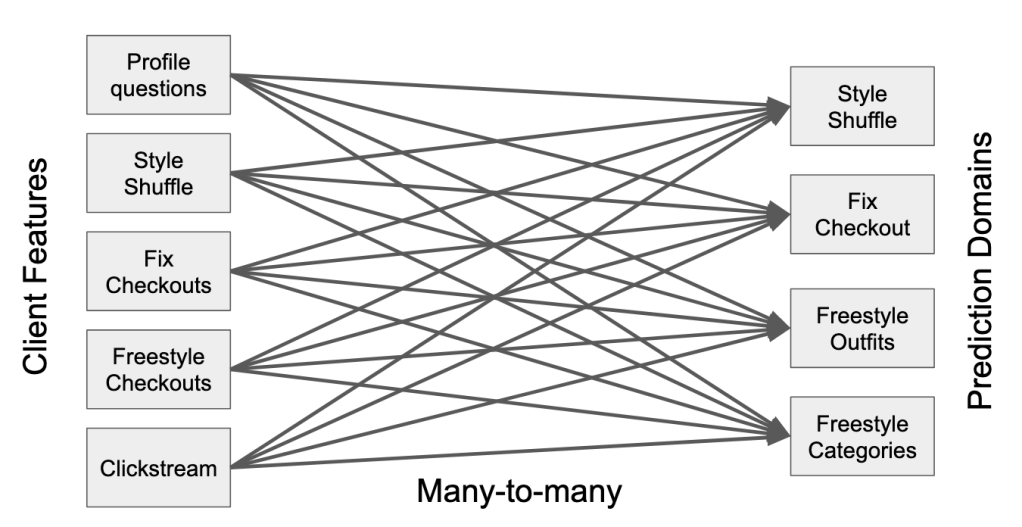
Figure 1: Many-to-many model 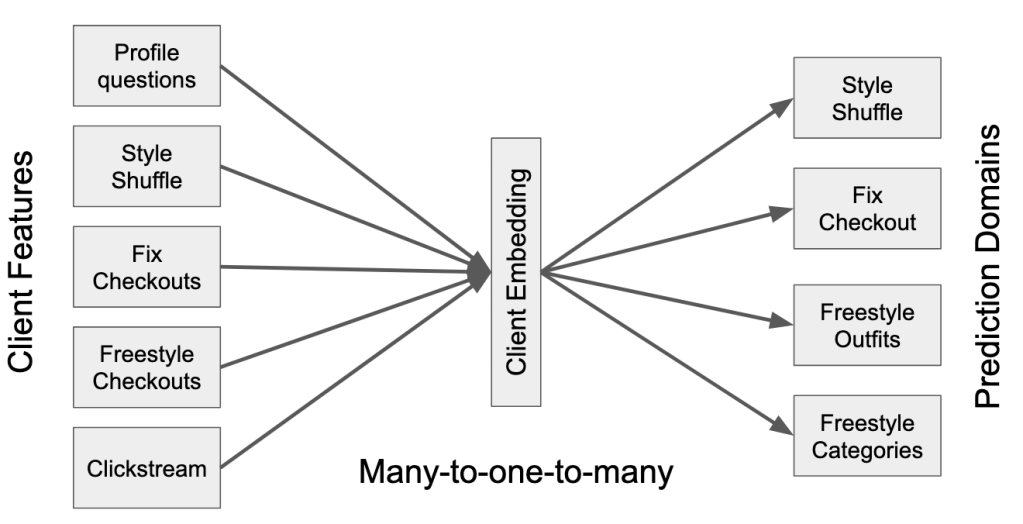
Figure 2: Many-to-one-to-many model
The benefit of this approach is that as the customer updates their preferences on the platform, their embedding will also update and this will generate more personalized recommendations across the platform domains. This method is very useful when having to generate multiple recommendations using shared data sources.
Another key element of CTSM is that the data are collected as a sequence of time-stamped events. This allows for real-time data processing and several modeling benefits such as:
- having a temporal context of events and understanding the preference of customers over time
- a time-safe design to prevent using future data to predict the past
- single event abstraction to simplify interfaces and ETL
- batch modeling based on timestamps to allow for real-time inference on new event data
While complex in design, this event-sequenced-based model is beneficial if you want to model customer interactions over time.
The third key element of the CTSM is to split “updates” from “targets”. Updates are pieces of information that change our knowledge about a customer such as changes to customer profiles based on the timestamp of an event vs targets which are the outcomes of interest such as the probability of sale that takes place at the time of prediction.
Splitting the observed updates from target predictions based on their relevant time stamps is beneficial when outcomes cannot be measured until after predictions are made or when different event schemas are being used.
Results
When implemented, CTSM showed 1-10% improvements in revenue, retention, and client satisfaction-related KPIs, a reduction in resource consumption due to fewer models being trained, lower maintenance, and paved the way for accelerated development for future improvements.
Q&A
Some interesting questions that came up during the Q&A:
- How are items handled? Item attributes either come from the merchant, are extracted from photos of the item, or are added by the customer in their in-platform feedback. Item embedding is handled with an embedding bag approach.
- How does CTSM handle the cold start problem? Since customers have to fill out a profile when they sign up, there is always preferential information to generate predictions from.
- How is CTSM evaluated? The model is either evaluated for accuracy with backtesting using a loss function for each target, or in production for KPIs with A/B testing.
For those interested, Kevin also mentions a blog post on the Stich Fix website that goes into more detail regarding CTSM.
