
Part One: Extracting Account Tweets and Tweets related to a Hashtag
In this post, I am going to show you how to extract tweets from twitter! Specifically the tweets related to a certain account (or twitter handle) and tweets related to a hashtag. Why might you extract this information from twitter at all?
Webscraping, scraping text from the web, automates the process of manually typing or copying and pasting information that we want from online sources. This could be regular websites or social media sites like Twitter. Social media supplies companies with direct reviews about their products and services, providing the best feedback for improvements.
In order to scrape twitter data, there is actually more work that goes into setting up everything, than actually extracting the tweets. So, let’s take this one step at a time.
Step One: Install and Load Your Packages
Step 1.a. There are several packages that will make the process of scraping tweets from Twitter much easier. The first step is to install the packages below:
install.packages("stringr")
install.packages("twitteR")
install.packages("purrr")
install.packages("tidytext")
install.packages("dplyr")
install.packages("tidyr")
install.packages("lubridate")
install.packages("scales")
install.packages("broom")
install.packages("ggplot2")
You only need to install packages the first time you scrape in R. The following times you webscrape in R, you can start with step 1.b.
Step 1.b. Load your packages with the below code:
library(stringr)
library(twitteR)
library(purrr)
library(tidytext)
library(dplyr)
library(tidyr)
library(lubridate)
library(scales)
library(broom)
library(ggplot2)
Step Two: Connecting R to Twitter
This next part is little tricky; you to connect you R with the Twitter API. The Twitter API or application programming interface, is what allows you to access Twitter’s data. In order to connect to the Twitter API, you first need to create a Twitter App.
Step 2.a. In order to create a Twitter app, make sure you are logged into your Twitter account and go to: https://developer.twitter.com/en/apps. Select “Create an App”.
Next, fill out the required fields with:
- The name of your app
- A description of what the app is for
- A website where the information will be used
- Further details about the purpose of the app
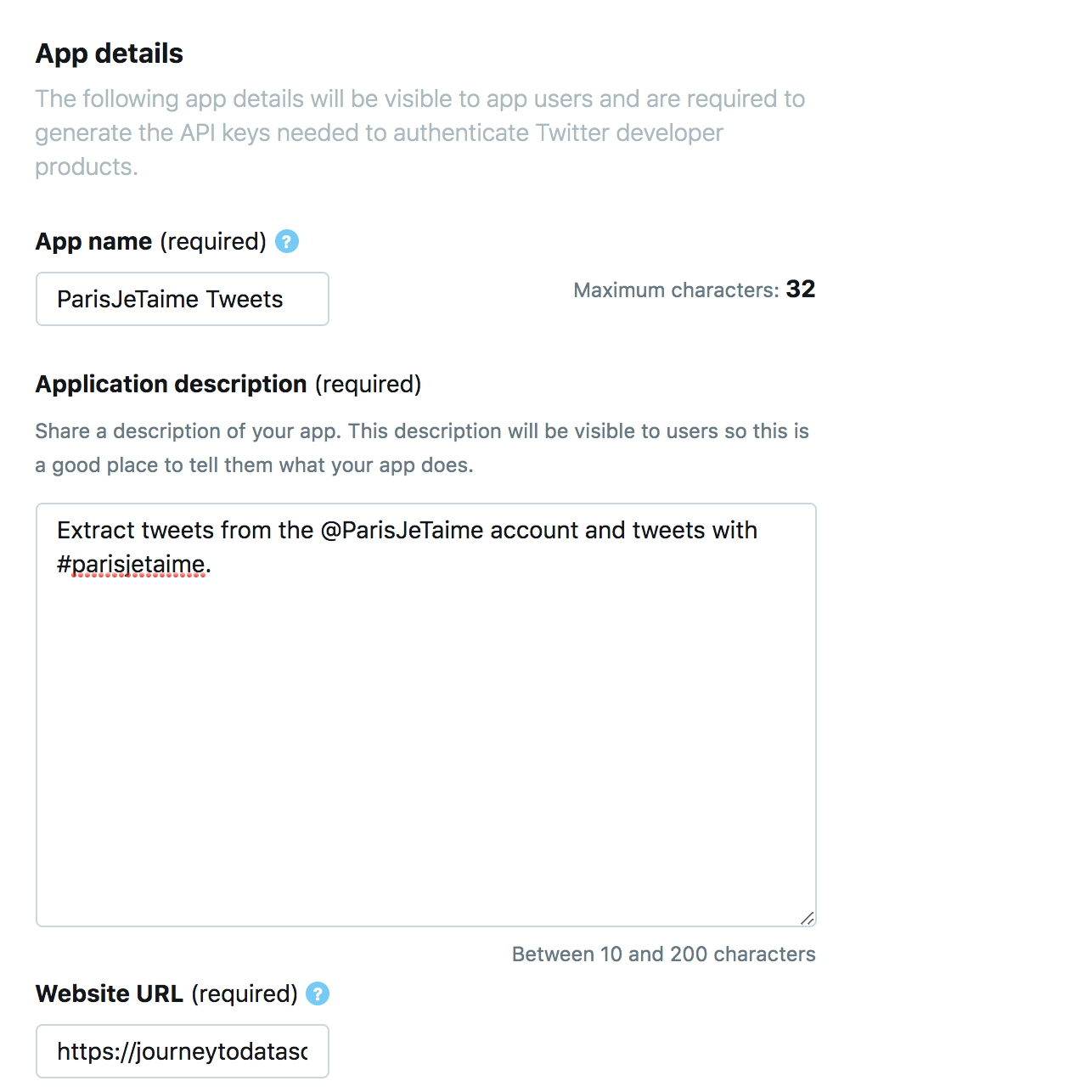
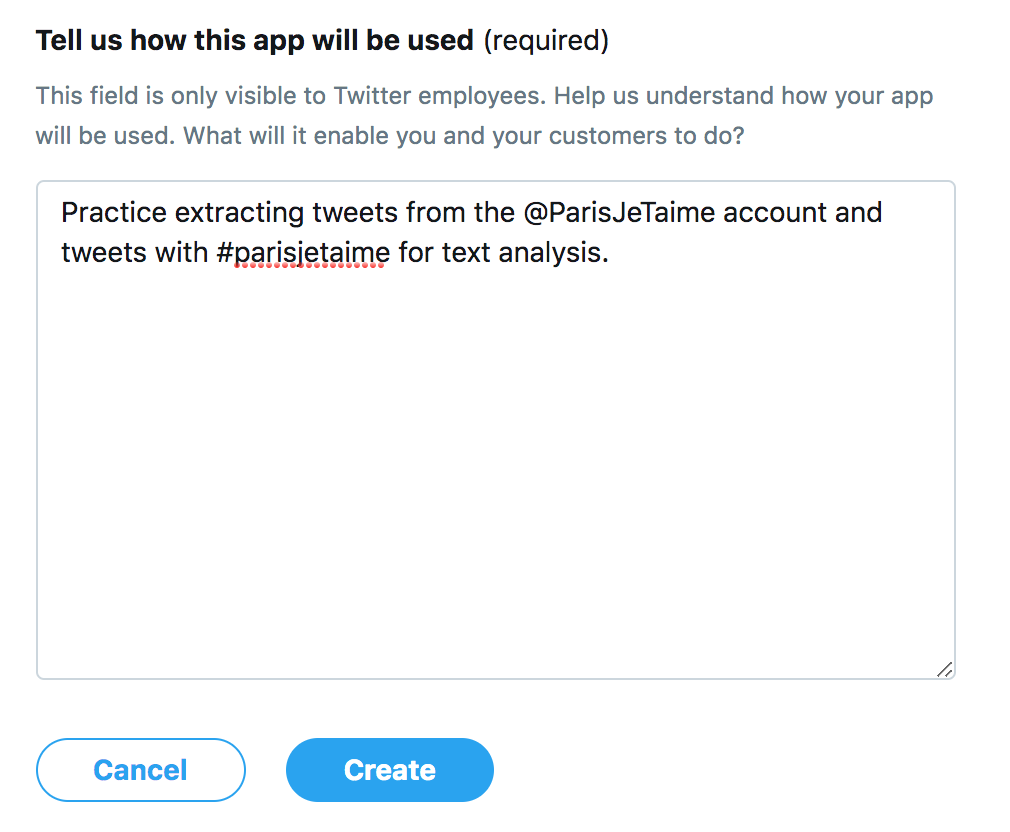
As you can see from my screenshots above, in honor of being in Paris today, I will be extracting tweets from the @ParisJeTaime account for the official Paris Tourist Office. I simply named my app ParisJeTaime Tweets, with a description that I will be extracting tweets. The application also asks for a website URL. I used my blog, since I will be publishing the data on here, but feel free to use any website as a filler in case you don’t have a blog to use for yourself. Lastly, I provided information again of how the app will be used.
Step 2.b. Once generated, head over to the “Keys and tokens” tab for your app (pictured below) where you will find the keys and tokens necessary to connect R, or RStudio, with the Twitter API.

Step 2.c. With all of your access keys and tokens, head back into R so you can establish a connection with Twitter. I recommend setting each of your keys and tokens to a variable; this way it will be easier to manage your code:
api_Key = "UpV34UlCER500Wt2L6moKzafQ"
api_Secret = "dClASQhAk2JPl6vCa1Y84bcm38FF6Ol2vXrKnBA2jnaCUxHYRU"
access_Token = "3289530502-HDTWQVZ5ygeBfkGge5uAF0ga9IFaH5eUjNlAVle"
access_Token_Secret = "mib41B7t0Cot1ifOJDsAlwHtYZzZUNRpLyTC54UPsfnsO"
Step 2.d. Use the code below to setup open authorization with Twitter data with your own key and token variables:
options(httr_oauth_cache=TRUE)
setup_twitter_oauth(consumer_key = api_Key, consumer_secret = api_Secret,
access_token = access_Token, access_secret = access_Token_Secret)
Once you see “Using direct authentication”, you are good to go!
Step Three: Scraping Tweets
The code for scraping tweets is fairly simple.
Step 3.a. If you want to scrape tweets from user or account timeline, you would need to use userTimeline() function. The code below shows how I used this function on the @ParisJeTaime account to extract their last 100 tweets.
ParisJeTaime <- userTimeline("ParisJeTaime", n = 100)
You can turn this data into a data frame with tbl_df(map_df()) functions. Let’s what this code and data frame looks like:
ParisJeTaime_df <- tbl_df(map_df(ParisJeTaime, as.data.frame))
head(ParisJeTaime_df)

As you can see from the data frame above, this data will need some cleaning before any analysis can be done on it. This we will be covering in future posts, but at least we have scraped some Twitter data!
Lastly, you may want to save your data frame as a file for later use. Using the code below will save your data frame to a CSV in your R directory path folder:
write.csv(ParisJeTaime_df, "ParisJeTaime.csv")
Step 3.b. If you want to scrape tweets with a certain hashtag, you will need to use searchTwitter() function. The code below shows how I used this function to extract that latest 100 tweets with #parisjetaime:
ParisJeTaimeHashtag <- searchTwitter("#parisjetaime exclude:retweets", n=100)
ParisJeTaimeHashtag_df <- tbl_df(map_df(ParisJeTaimeHashtag, as.data.frame))
write.csv(ParisJeTaimeHashtag_df, "ParisJeTaimeHashtag.csv")

As we can see again from these tweets, a lot of data cleaning will be necessary. Not to mention, I may need to learn some French as well.
Look for future posts on how to clean data like this from the web, and what kind of analysis can be done with it. Click here for reference code.

[…] my last post, I covered how to extract tweets from a specific Twitter account and tweets related to a specific […]
LikeLike
[…] a previous post, I introduced how to scrape tweets from Twitter. Specifically, I covered how to connect R to the […]
LikeLike
[…] a previous post, I introduced how to scrape tweets from Twitter. Specifically, I covered how to connect R to the […]
LikeLike